SVX日記
2024-02-02(Fri) ハスに構えつつAIをカジってみる
計算機の最底辺部分から理解している自分からすると、平均的な日本人のAIに対する期待は少々過大であるように感じる。まぁ、自分が現在所属する「割と日本を代表するIT企業である○○」の平均的な社員のそれも、ほぼ似たようなものと感じるので、無理もないところであろうが。
IT技術に関する知識レベルが完全にゼロである自分の母親は、8bit機が主流の頃ですら「(オセロなどで)コンピュータに勝てるわけないでしょ」とノタマっていた。総じて仕組みに疎いほど、仕組みに対する期待が高い傾向にあると言えるだろう。そういうことなので自分のAIへの期待は平均よりだいぶ低い。それらしく模倣をしているだけにしか見えないのだ。まぁ、それらしく模倣ができることはスゴいことなのだけれど。
そのように、ややAIに対して否定的な自分であるが、なぜか「AI調査チームの長」をやらされることになった。あまり積極勧誘もしなかったのでメンバも数人。チーム名は「AIを診る会」と命名した。「診る」とか「桜?」とかいうあたりに皮肉を込めている。仕事の一環ではあるが、楽しむことが第一、という基本方針。そうしても咎められないし、関連書籍もホイと買ってくれるあたりは、ウチの会社もそこそこだと思えるが。
基本、自分はメンバを誘導することが責務なのだが、自分で手を動かさずにいるのは性に合わない。なので、少しは何かをやろうと、買った書籍が「初めてのTensorFlow.js」であった。やはりAIの基本は多項式。Pythonには吐気がするが、CoffeeScriptがある限りJavaScriptが許せるという自分にとって、JavaScriptでTensorFlowが使えるというのは天の恵みと思えたのである。
ところが、だ。この本は内容が薄い(と最初は思った)。サンプルを動かすだけで、肝心の機械学習の方法についてほとんど触れられていない。機械学習を行う記述がないまま、画像認識に進んでしまっている。そういう「使うだけ」っていうのは、自分の指向ではないのだ(と最初は思った)。
んが、実際にサンプルを動かしてみて気づいたのである。既に「AIはゼロから組み上げるものではないのだ」ということに。暗号通信を伴うプログラムを作る時、暗号技術の学習から始めるべきか? 3D表示を伴うゲームを作る時、ベクトル演算の学習から始めるべきか? ノーである。普通は既存のライブラリを使うべきなのだ。写真中の物体識別を行いたい時は、それ用の既存のモデルである「Inception v3」を使うべきなのだ(いや、基盤部分に取り組むのも価値のある仕事だけれども)。
今回、AIの調査を始めて最大の収穫が、上記の事実に気づいたことなのであった。それに気づいた後に「初めてのTensorFlow.js」を読み直せば、実にバランスのよい内容であると思える。実用的な使い方を示した後には、訓練方法にも触れているし、既存のモデルに独自の学習内容を加える「転移学習」も扱っているのだから(まだ十分に読んでないけど)。
で、写真中の物体識別のサンプルを動かしてみると、なかなかにいい感じの識別具合であり、ムズムズと自分のものにしたくなってくるのである。自分にとって「自分のものにしたくなる」とは、自分が自由に使える状態にするということである。具体的には、ブラウザ上で動いていてもその先はないので、Node.jsで手元で動くようにサンプルを改変し、環境ごとコンテナ化し、PV経由で写真を食わせられるようにし、連続して識別ができるようにし、CoffeeScript化し、結果をテキストファイルに出力できるような状態にする、ということである。
というわけで、コンテナの定義ファイルを置いておく。
# 1
carton, /var/lib/pv/svxdiaryimages2023/s20230128_0.jpg, 1
envelope, /var/lib/pv/svxdiaryimages2023/s20230128_0.jpg, 2
packet, /var/lib/pv/svxdiaryimages2023/s20230128_0.jpg, 3
# 2
shower cap, /var/lib/pv/svxdiaryimages2023/s20230128_1.jpg, 1
envelope, /var/lib/pv/svxdiaryimages2023/s20230128_1.jpg, 2
plastic bag, /var/lib/pv/svxdiaryimages2023/s20230128_1.jpg, 3
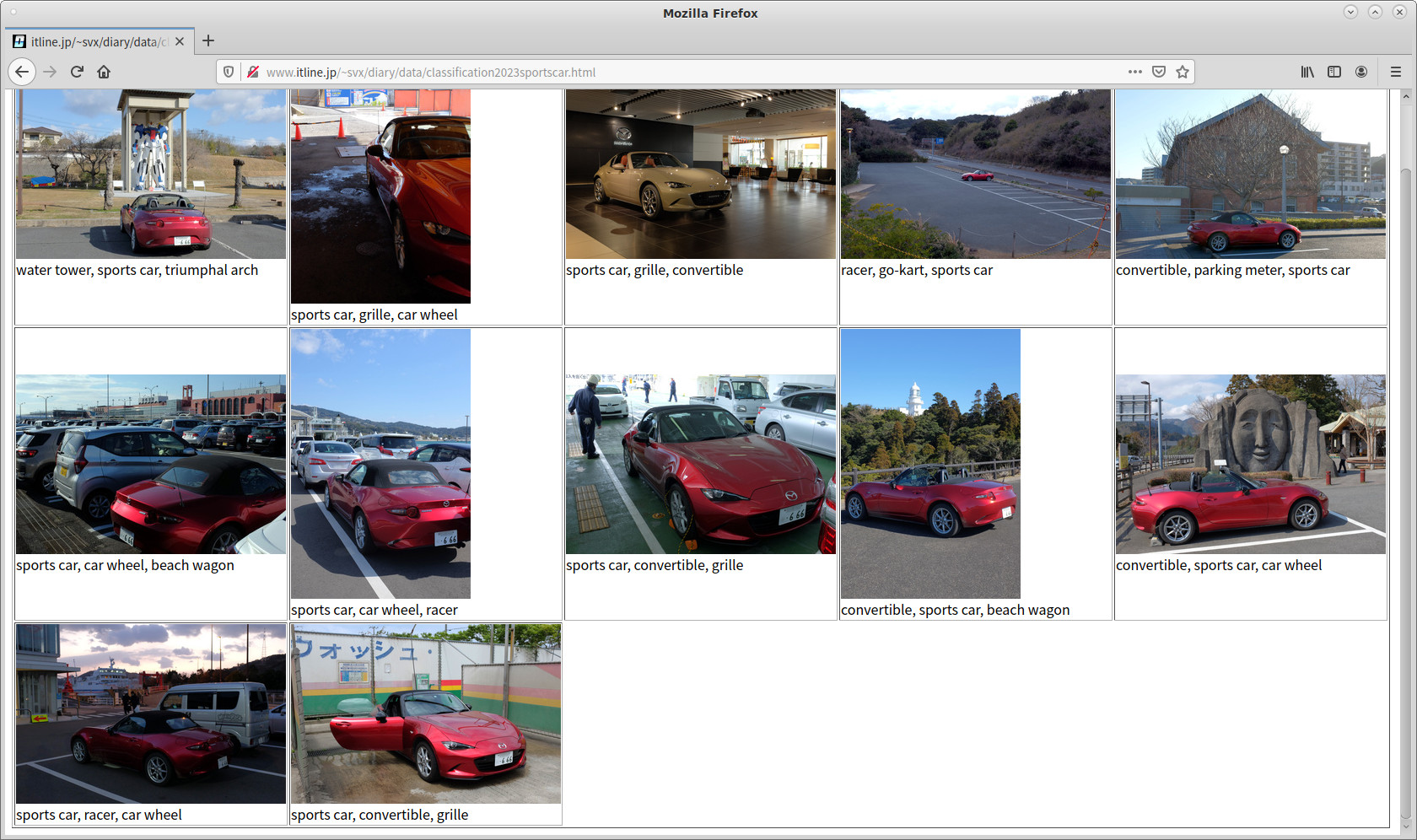
:上記までくれば、それをHTMLに変換するスクリプトを書くのは容易であり、変換した結果がこれである。
「sports car」で絞り込まず、2023年の全ての写真を判別した結果がこれである。「Inception v3」は海外で訓練されたモデルであり、識別結果は1001の英名詞に限られるので、やや不自然な識別結果も含まれるが、それでも高水準の識別結果であると思える。例えば「ごはん」は「mashed potato」と識別されているが、見た目も位置づけ(?) も大きく間違ってはいない。
ちなみに、このブログは外部のVPSで独自に動かしているものなので、手元のコンテナに画像データを食わせるため、VPSの「/home/user」上に「cp -lr」で画像のハードリンクを含むディレクトリを作成し、そこを「sshfs」でリモートmountし、それをPVとしてポイントして処理を行った。なので、今回は画像のベタなコピーを行うことなく処理を完了している。我ながら、これはノウハウだな(別にVPS上でコンテナを動かしてもよかったのだけれども)。
