SVX日記
2020-03-09(Mon) 痛い字……もとい、異体字含有文書ジェネレータ
一口に文字情報といっても、バイト列として右から左へ渡すだけのアプリ(例えばsendmail)にとっては、対応もクソもないし、画面に表示、検索、編集までするアプリ(例えばウェブブラウザ)にとなると、使っているフォントが対応しているかどうかという問題にまで飛び火する。とはいえ、大概Linuxはサーバとして使われるのでフォントまでは関係せず、対応の可否は「アプリの文字情報の扱い方次第」ということになる。しかしながら「文字の仕組みについて何もわかっていない人」にそれを言っても何も進まないので……まぁ、適当にそれっぽい回答をして終わらせることになるのだ。
それはさておき、Unicodeは絵文字を入れだしてから、世界的な大喜利が始まったみたいになっていて、目が離せない。そろそろ、各企業のロゴを入れてやるから金払え、というビジネスをやりだしそうでワクワクが止まらない。
・字の示す意味は同じであるが、字形(デザイン)だけ違う字
・文字列検索などでは、区別されないべき
・当該の文字コードの直後に「字形選択子」を記述することで表現
・字形選択子という存在自体はUnicodeで規定する、が
・字形選択子の各々にどんな字型を割り当てるかは各国で適当に決めな
・最近のLinuxでは対応しているアプリ/フォントが増えているとはいえ、意図的に表示させなければ、それが表示されていることを確認することも難しいわけで、その表示方法を体感する意味でも、異体字を含む文書を生成するツールを自作してみた。名付けて「異体字含有文書ジェネレータ」。実行すると、指定する異体字のカタログライクなHTMLファイルを出力するというもの。
あとは、それを各アプリで読んでみればいい。対応しているFedora31のFirefox71ではこんな表示になる。左の列以外は字形に差がないが、これはフォントが対応していないということである。標準のVLゴシックはかなり対応している反面、古いmacからぶっこ抜いたOsakaが対応していないのは当然として、最新のIPAM-incho(ipa-mincho-fonts-003.03-15)が対応してないのは割と意外。
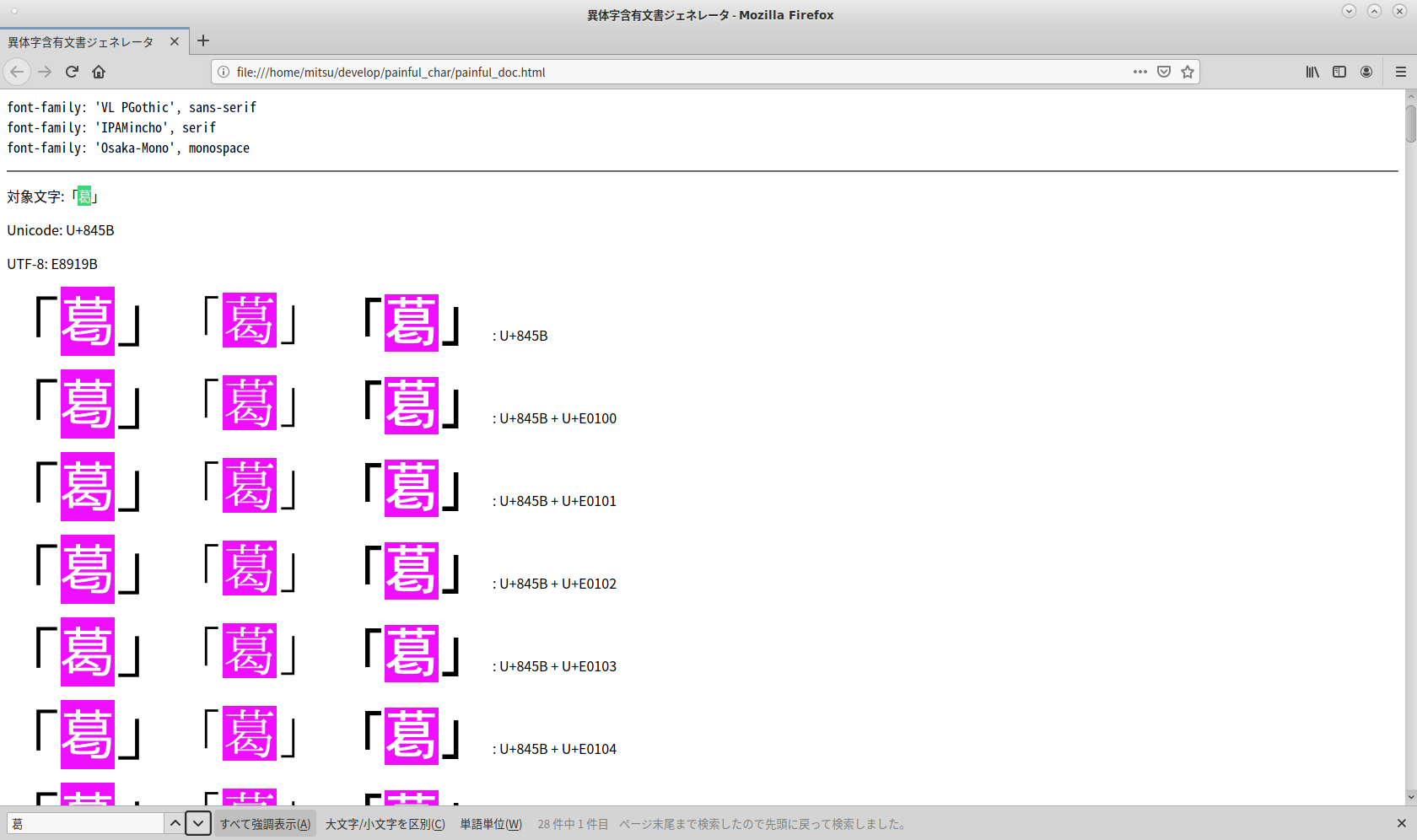
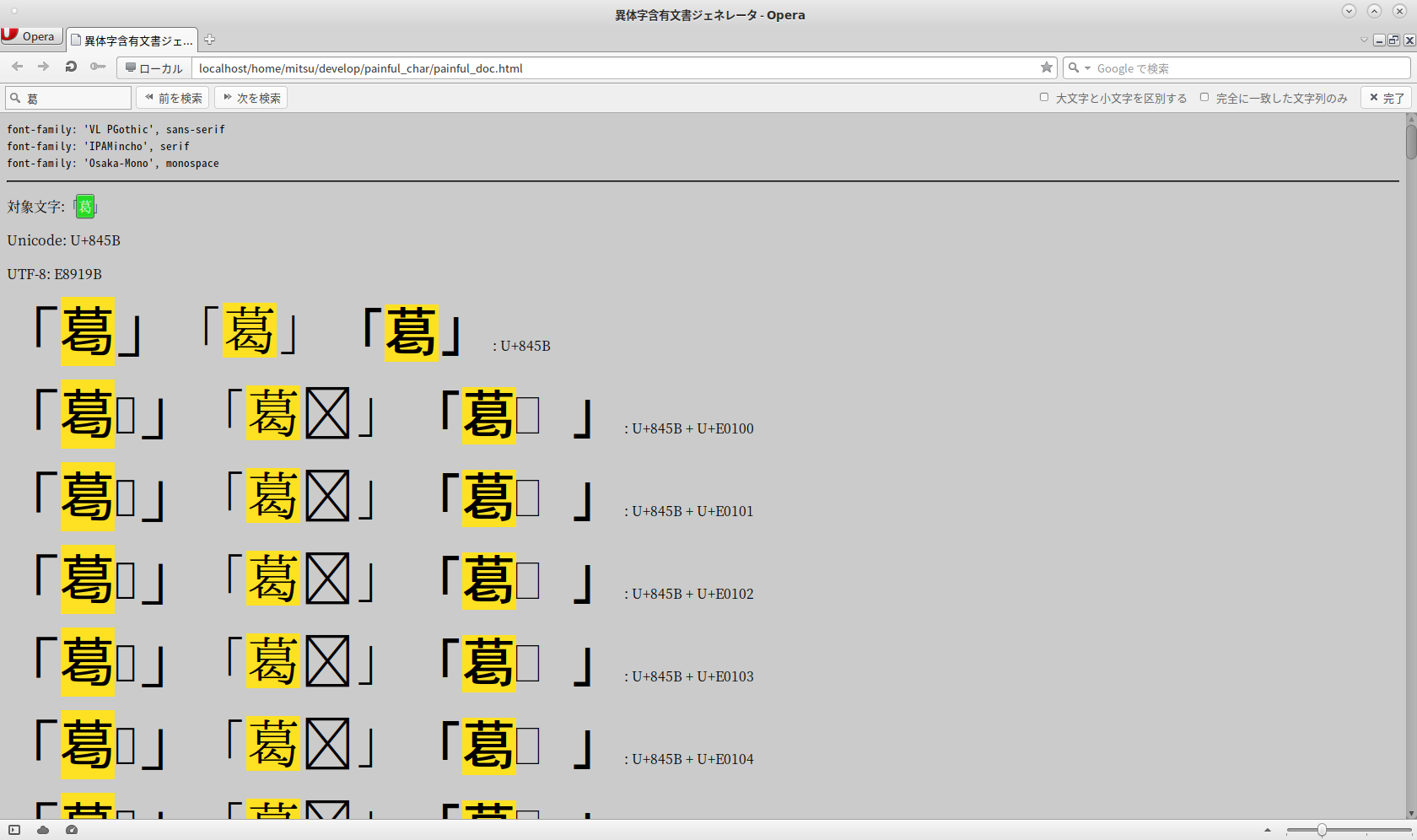
emacsは対応しているとのことだがこんな表示になる。ない文字は「ない」ことをと明示する方針というか、字形選択子の部分だけコピペすることもできるようだ。これでも、文字列検索で同一視する動作は行われる。
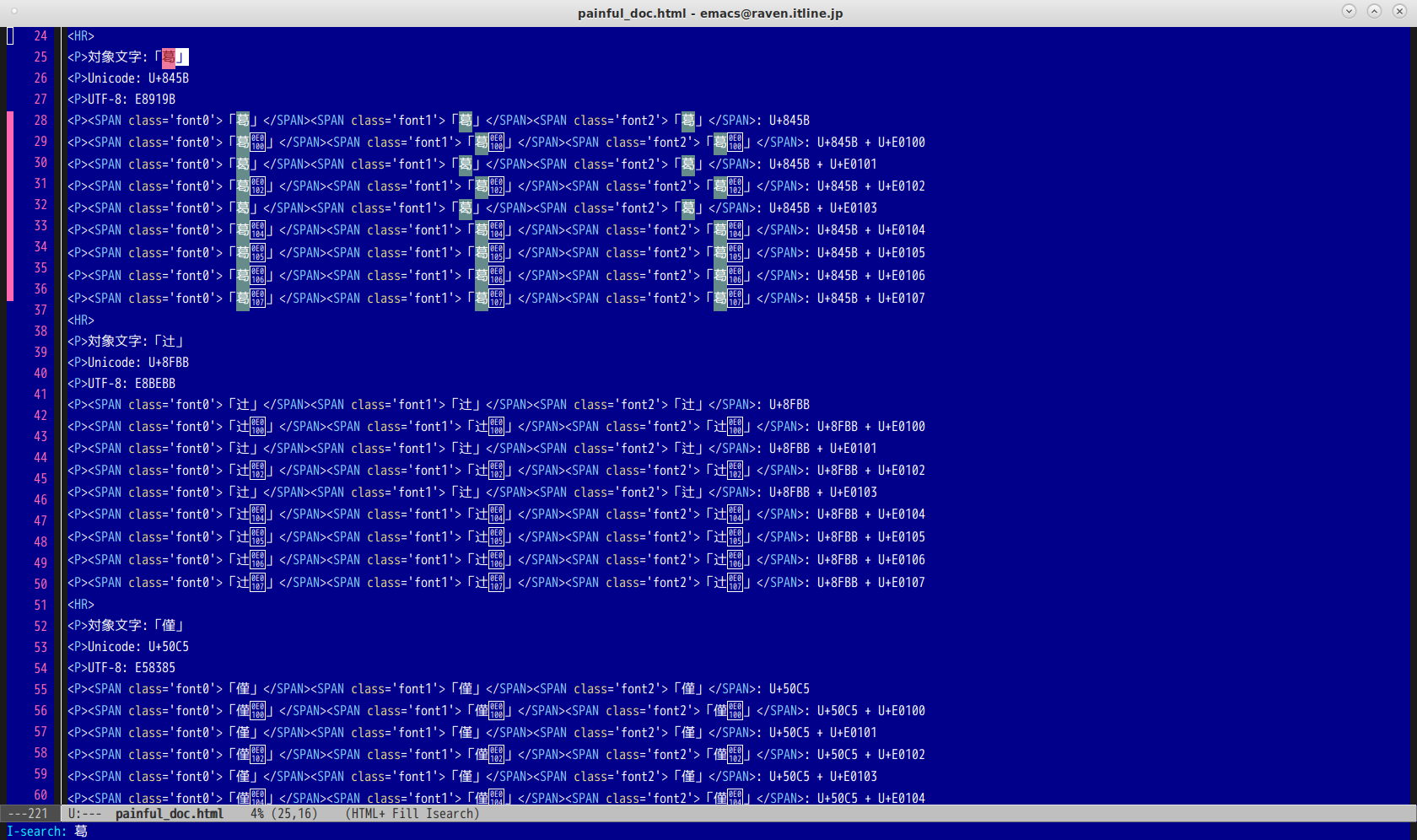
というわけで、意外と「異体字」を扱う仕組みは整備されいてる印象である。というわけで、一番の受益者であろう「葛……」もとい「葛󠄁飾区」のサイトに行ってみる。なるほど。ちゃんと「人」が入っている字だな……って「ヒ」の字も混在しているぞ? まさか「人」が入っている字は画像中だけ? ……ていうか、わたしの予想に反して、この「葛」と「葛󠄁」が同じに見えていないでしょうね?
$ wget -O - http://www.city.katsushika.lg.jp/ | od -t x1z | grep f3しかし、どうにも釈然としないのが、むしろ一般的すぎる異体字の扱いである。「髙(はしご高)」「﨑(立つ崎)」「𠮷(土吉)」など。なんでこれらは「異体字」扱いされず、異なる文字コードを振られてしまっているのだろうか。高橋さんも、髙橋さんも、宮崎あおいも、宮﨑あおいも、吉野家も、𠮷野家も、区別なく検索されるべきだよね。
つうわけで、スクリプトとその出力結果(html)を置いておく。各自の環境、ブラウザ、アプリでアクセスするなどし、この先は君の目で確かめてくれ!
