SVX日記
2023-12-06(Wed) WebAssemblyでトラディショナルな回転技術を再現
というわけで、9月末頃に「やろう」と思い立ってから2ヶ月チョイもかかってしまった。まぁ、だらだらと取り組んでいたせいもあるが、初めての言語、かつ、相手が未知の仕様を含むアセンブラでは効率が上がらなかったのも無理はないかな。
そう「WebAssemblyのひとつだけの使い道」とは、過去に実装に成功した「回転、拡大、縮小機能」をWebAssemblyを使って高速化することなのであった。WebAssemblyは計算やメモリ操作しかできず、複雑な関数計算も苦手なのだが、1980年台のトラディショナルな回転、拡大、縮小技術は、加算処理を山ほど行うだけなので、用途としてピッタリなのだ。

wasmのコードは試行錯誤で書くには記述性が低すぎるし、可読性も低すぎる。ので、考え方の図と併せて、Rubyで作ったプロトタイプのコードも載せておく。処理はほぼ同じ。アセンブラ頭で書いたRubyコードw。これも相当に考えないと何をやっているのかわからんと思うが。
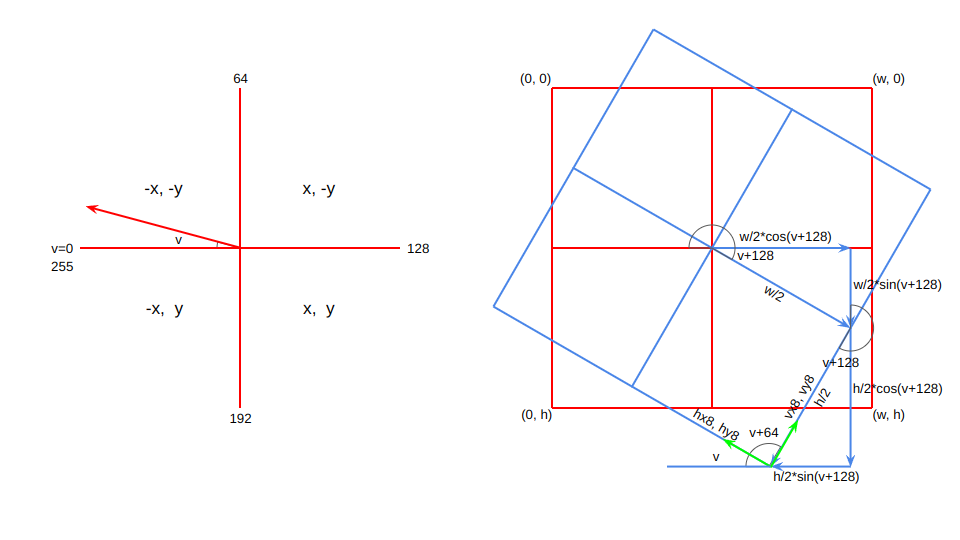
rxy = vxys[v + 128] # サンプリングxy開始点計算用
hxy = vxys[v] # 水平方向サンプリングxy間隔
vxy = vxys[v + 64] # 垂直方向サンプリングxy間隔
dest_adr = w * h # 描画先アドレス
dx = w >> 1; dy = h >> 1
_vx8 = dx * rxy[0] - dy * rxy[1] + (dx << 8) # サンプリングxy開始点
_vy8 = dx * rxy[1] + dy * rxy[0] + (dy << 8)
begin
x = w # 水平方向カウンタを初期化
_hx8 = (_vx8 += vxy[0]) # サンプリング位置を垂直方向に進め、水平方向の初期位置としてセット
_hy8 = (_vy8 += vxy[1])
begin
dest_adr -= 1
_hx8 += hxy[0]; _hy8 += hxy[1] # サンプリング位置を水平方向に進める
(_hx8 < 0 or _hx8 >= (w << 8)) and next # サンプリング範囲外チェック
(_hy8 < 0 or _hy8 >= (h << 8)) and next
src_adr = (_hy8 >> 8) * w + (_hx8 >> 8) # サンプリングアドレス計算
color = LegacyGraphics.point(src_adr & msk64, src_adr >> x64)
win.pset(dest_adr & msk64, dest_adr >> x64, color)
end until((x -= 1) == 0)
end until(dest_adr == 0)CPUが8bitの時代、大半はBASIC、処理速度が必要な部分のみ「CALL」や「USR」で機械語サブルーチンを呼び出す、というプログラミングスタイルがあったが、まさにそれと同じようなスタイルになっている。
回転したパターンはキャッシュされるので、画面ではふたつのテトランを回しているものの、計算しているのはひとつ分だし、1回転した後はすべてキャッシュからの表示となる(呼び出し側からは透過的にそうなる)。今回のパターンは四隅までミッシリの128x128サイズなので端が欠けるが、透過処理もバッチリできているので、実用するなら256x256で回すことになるだろう(256x256なら181x181(256/√2)の大きさまで欠けずに回せることになる)。
今回の表示は以前に作ったスケルティウスのエンジンを流用しているので、逆に言えば、既にシューティングゲームにそのまま利用できる形になっている。また別途、複数のコードをリンクする仕組みを自作しており、APIを揃えているので、リンクする物件を'rotnscl_wasm.bean'から'rotnscl.bean'に変更するだけで、WebAssemblyを使わないバージョンに戻すことができる。
実は、JavaScriptのコンソールログを開くと、フレームレートや負荷率が出力されるようになっているのだが、WebAssemblyを使わないバージョンだと、負荷率が150%前後となり、60であるべきフレームレートが30前後に落ちてしまう。
now: ,1701848213042,frames: ,20, load: ,174,%
now: ,1701848215409,frames: ,28, load: ,180,%
now: ,1701848218383,frames: ,15, load: ,150,%
now: ,1701848220384,frames: ,32, load: ,144,%
now: ,1701848221614,frames: ,53, load: ,6,% ※キャッシュが完了
now: ,1701848222597,frames: ,62, load: ,0,%ちなみに、今回のwasmモジュールは最大512x512のパターンまで回せるのだが、WebAssemblyを使わないバージョンだと、負荷率は2500%を越え、フレームレートは2前後と紙芝居以下のレベルになってしまう一方で、WebAssemblyバージョンなら、負荷率は概ね20%以下で、まだまだ鼻歌交じりとなる。128x128と512x512では面積比が16倍なので、150%が2400%になることは理屈に合う。WebAssemblyなら512x512でも20%前後ということは、軽く100倍を越える速度が得られているということになる。
そりゃ、直接にニーモニックで書いて、しかも割とカリカリに最適化してあるんだから、そうこなくっちゃってとこだ。100倍というのは苦労に見合う結果に思える。先には数倍という話も聞いたが、あれはRustなどからコンパイルした場合の話なのだろうな。ちなみに「割とカリカリに最適化してある」ものの、今回はベクトル演算命令は使っていない。それを使えばさらに速度は上がるはずだ。まぁ、上がっても20%以下だろうが。
